
webgpu-graph
上一篇
经典 GPGPU 的实现原理
下一篇
使用 Web Components
Loading...
我们参考 cuGraph 以及其他 CUDA 实现,基于 g-plugin-gpgpu 背后的 WebGPU 能力实现常见的图分析算法,达到大规模节点边数据量下并行加速的目的。
对比 G6 目前提供的 CPU 串行版本有很大提升。
| 算法名 | 节点 / 边 | CPU 耗时 | GPU 耗时 | Speed up |
|---|---|---|---|---|
| SSSP | 1k 节点 5k 边 | 27687.10 ms | 261.60 ms | ~100x |
| PageRank | 1k 节点 500k 边 | 13641.50 ms | 130.20 ms | ~100x |
在使用前需要确认运行环境与数据这两项前置条件。
目前(2022-3-21)在 Chrome 94 正式版本以上即支持 WebGPU,但由于我们使用最新的 WGSL 语法,推荐更新浏览器到最新版。
目前在生产环境使用,需要启用 Origin Trial 以支持 WebGPU 特性(Chrome 100 以上将不再需要):
<meta> 标签,附上上一步获取的 Token,例如通过 DOM API:const tokenElement = document.createElement('meta');tokenElement.httpEquiv = 'origin-trial';tokenElement.content = 'AkIL...5fQ==';document.head.appendChild(tokenElement);
我们的官网已经添加了该 token,因此只需要使用最新版 Chrome 就能正常运行全部算法示例。
我们使用 G6 的图数据格式,它也是以下所有算法的第一个固定参数。在内部我们会将其转换成 GPU 内存友好的图存储格式例如 CSR(compressed sparse row):
const data = {// 点集nodes: [{id: 'node1', // String,该节点存在则必须,节点的唯一标识x: 100, // Number,可选,节点位置的 x 值y: 200, // Number,可选,节点位置的 y 值},{id: 'node2', // String,该节点存在则必须,节点的唯一标识x: 300, // Number,可选,节点位置的 x 值y: 200, // Number,可选,节点位置的 y 值},],// 边集edges: [{source: 'node1', // String,必须,起始点 idtarget: 'node2', // String,必须,目标点 id},],};
如果数据格式不满足以上要求,算法将无法正常执行。
我们提供以下两种方式使用:
创建一个 WebGPUGraph,内部会完成画布创建、插件注册等一系列初始化工作。完成后直接调用算法:
import { WebGPUGraph } from '@antv/webgpu-graph';const graph = new WebGPUGraph();(async () => {// 调用算法const result = await graph.pageRank(data);})();
如果已经在使用 G 的 Canvas 画布进行渲染,可以复用它,并执行以下操作:
import { Canvas } from '@antv/g';import { Renderer } from '@antv/g-webgpu';import { Plugin } from '@antv/g-plugin-gpgpu';import { pageRank } from '@antv/webgpu-graph';const webgpuRenderer = new Renderer();webgpuRenderer.registerPlugin(new Plugin());const canvas = new Canvas({container: 'my-canvas-id',width: 1,height: 1,renderer: webgpuRenderer,});(async () => {// 等待画布初始化完成await canvas.ready;// 通过渲染器获取 Deviceconst plugin = webgpuRenderer.getPlugin('device-renderer');const device = plugin.getDevice();// 调用算法,传入 device 和图数据const result = await pageRank(device, data);})();
以下所有算法均为异步调用。
为图中每一个节点计算 PageRank 得分。
参数列表如下:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| graphData | GraphData | true | 图数据 |
| epsilon | number | false | 判断 PageRank 得分是否稳定的精度值,默认值为 1e-05 |
| alpha | number | false | 阻尼系数(dumping factor),指任意时刻,用户访问到某节点后继续访问该节点指向的节点的概率,默认值为 0.85。 |
| maxIteration | number | false | 迭代次数,默认值为 1000 |
返回值为一个结果数组,包含 id 和 score 属性,形如 [{ id: 'A', score: 0.38 }, { id: 'B', score: 0.32 }...]。
其中数组元素已经按照 score 进行了从高到低的排序,因此第一个元素代表重要性最高的节点。
参考以下 CUDA 版本实现:
使用方式如下,示例:
const result = await graph.pageRank(data);// [{id: 'B', score: 0.3902697265148163}, {}...]
在较大规模的点边场景下有非常明显的提升:
| 算法名 | 节点 / 边 | CPU 耗时 | GPU 耗时 | Speed up |
|---|---|---|---|---|
| PageRank | 1k 节点 500k 边 | 13641.50 ms | 130.20 ms | ~100x |
⚠️ 目前我们的实现需要使用 V * V 的存储空间,因此节点数量太多会触发 JS 的数组的 RangeError。
单源最短路径,即从一个节点出发,到其他所有节点的最短路径。
参数列表如下:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| graphData | GraphData | true | 图数据 |
| source | string | true | 源节点 id |
| weightPropertyName | string | false | 边的权重属性字段名,若不指定,则认为所有边权重相同 |
| maxDistance | number | false | 最大距离,默认为 1000000 |
返回值为一个结果数组,形如 [{ target: 'A', distance: 10, predecessor: 'B' }, ...]。其中数组中每一个元素包含以下属性:
target 路径终点 iddistance 从源节点到终点的距离predecessor 到达 target 的上一个节点 id参考以下 CUDA 版本实现:
以下图为例,我们希望获取以 A 为源节点到所有节点的最短路径:
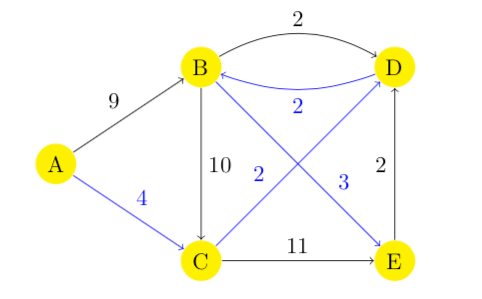
在图数据中,边的权重字段为 weight,示例:
edges: [{source: 'A',target: 'B',weight: 9,},// 省略其他边];
对于返回结果的解读方法如下,如果我们想获取从 A 到 E 的完整最短路径,可以先从最后一个元素看起,发现 E 的前序节点为 B,然后 B 的前序节点为 D,最终可以得到 A -> C -> D -> B -> E 这样一条完整的最短路径:
const result = await graph.sssp(data, 'A', 'weight');// 结果如下[{ target: 'A', distance: 0, predecessor: 'A' },{ target: 'B', distance: 8, predecessor: 'D' },{ target: 'C', distance: 4, predecessor: 'A' },{ target: 'D', distance: 6, predecessor: 'C' },{ target: 'E', distance: 11, predecessor: 'B' },];
需要注意的是,如果起始节点和终点为同一节点,distance 等于 0。
在较大规模的点边场景下有非常明显的提升:
| 算法名 | 节点 / 边 | CPU 耗时 | GPU 耗时 | Speed up |
|---|---|---|---|---|
| SSSP | 1k 节点 5k 边 | 27687.10 ms | 261.60 ms | ~100x |
Accelerating large graph algorithms on the GPU using CUDA
https://github.com/divyanshu-talwar/Parallel-DFS
K-Core Decomposition with CUDA
https://github.com/adamantmc/CudaCosineSimilarity
https://github.com/hamham240/cudaGraph/blob/main/src/algos/cudaCD.cu